
Key Takeaways
- LLMs don’t retrieve facts. They reconstruct them from a hazy, compressed memory of the internet, which limits accuracy.
- Giving models structured, expert-verified context transforms their reasoning, making their outputs dramatically more reliable.
- The future of trustworthy AI won’t come from bigger models, but from better grounding in high-quality data.
Think about the last time you tried to recall something you read a year ago: a detail from a report, a statistic, a quote. You probably remembered the outline, but not the nuance.
That’s exactly how large language models (LLMs) think. Their “knowledge” is a compressed blur of the internet: extensive and imaginative, but unreliable.
AI researcher (former head of AI at Tesla and founding member of OpenAI), , called this a “hazy recollection.”
By contrast, the context you feed an LLMs is its short-term memory: vivid, precise and ready for reasoning.
Just as a person thinks more clearly with a report open in front of them than by guessing from memory, an AI model becomes dramatically smarter when it reasons from a credible, authoritative source instead of its own blurry recollections.
Inside AI’s hazy memory
LLMs, like OpenAI’s GPT-4, Google’s Gemini, and Anthropic’s Claude, are trained on vast datasets: trillions of words from the internet, books, academic papers and code. During this pre-training phase, the model learns to predict the next word in a sequence. Through that process, it builds internal representations of how language—and by extension, the world—works.
Karpathy describes this process as an act of extreme compression. For example, Llama 3 70B (Meta's open-source LLM) was trained on That’s like trying to fit the entire internet into a thumb drive. To make that possible, the model doesn’t memorize facts but learns statistical patterns about how words, ideas and facts tend to appear together.

The trade-off is power without precision. By compressing the world’s text into probabilities, the model loses detail, source fidelity and chronology.
So, when you ask ChatGPT about an industry, it’s not retrieving information but reconstructing a likely answer from fragments of patterns it once saw: part press release, part blog post, part government data, all blended together into something that sounds authoritative. In Karpathy’s words, it’s reasoning from a “hazy recollection of the internet.”
The power of context: Working memory for machines
If pre-training is a model’s long-term memory then context is its working memory, or what it’s thinking about right now.
Context refers to the information you feed a model at runtime, meaning the text or data within its context window, everything it can actively “see” while generating a reply. It’s what you type into ChatGPT, or what a RAG-based system like Phil retrieves at the moment of reasoning. Modern LLMs such as GPT-4 can now process over 100,000 tokens (roughly 75,000 words) in a single context window.
The distinction between long-term and working memory is crucial. Pre-training compresses the world’s information into a few billion parameters, creating broad but blurry recollections. Context, by contrast, is live and specific. It lets the model reason with real data rather than fuzzy approximations of it.
As Karpathy explains, when you ask an LLM about a book it remembers from training, you’ll get an answer that’s roughly right. But if you paste the full chapter into its context window, the responses become dramatically sharper and more reliable because it’s now reasoning from working memory, not distant recollection.
That same principle underpins Phil, 91ÉçÇř’s AI research assistant, and 91ÉçÇř’s Microsoft Copilot Connector. 91ÉçÇř’s AI solutions do not rely on generic internet training data; they reason directly from 91ÉçÇř’s structured, analyst-written reports. Every insight generated is grounded in verified data, not a best guess. This anchoring turns AI from an imitator into an interpreter, capable of producing credible, decision-ready insights in seconds.
Case study: How data-grounded AI outperforms generic industry analysis
Let’s see this in practice. To illustrate how access to structured, analyst-verified data changes the quality of AI output, I ran the same set of industry analysis prompts using ChatGPT’s free plan and 91ÉçÇř’s Microsoft Copilot agent, which connects to our research. While both tools are powered by the same underlying ChatGPT model, 91ÉçÇř’s Copilot connector layers that model with direct access to our structured, analyst-verified industry research, allowing us to isolate the impact of data context rather than the model itself. The goal was not to test writing quality, but to evaluate how each system reasons when asked to support real analytical tasks such as risk assessment, industry profiling and credit decisions.
Across multiple prompts and industries, the pattern was consistent. The free versions of ChatGPT produced fluent, high-level narratives that sounded plausible but remained generic and difficult to validate. The Copilot integration, by contrast, anchored its responses in 91ÉçÇř’s organized datasets, surfacing quantified benchmarks, forecasts and standardized risk signals that can be traced, compared and used in decision making. The examples below show how that difference plays out in practice.
Industry strengths: “What are the strengths of the US Apartment Rental Industry?”
When asked to provide industry strengths in the context of a SWOT analysis, ChatGPT produced a set of broad strengths about stable housing demand, diversified tenants across metros and barriers to entry in gateway cities. The content was coherent and confidently written, but none of it referenced real data. It could describe general patterns found across the internet, yet it could not anchor its insights in verified metrics or forward-looking trends.
Microsoft Copilot, by contrast, grounded its strengths in specific 91ÉçÇř data points. It highlighted that 80.7 percent of the US population lives in urban areas, a figure expected to rise to 87.4 percent by 2050, reinforcing long-term rental demand in metropolitan markets. It also cited that nearly 49.7 percent of renter households are cost-burdened, a structural factor that keeps many households in the rental market for longer periods. These are not approximations or recollections. They are concrete, analyst-verified inputs that immediately elevate the quality and credibility of the output.

Because Microsoft Copilot reasons directly from 91ÉçÇř’s structured content, it can also incorporate forecast data, demographic trends and risk drivers, making the analysis decision-ready rather than merely descriptive.
Risk assessment: “What is the risk profile of this industry?”
When asked to describe the risk profile of the US apartment rental industry, ChatGPT returned a familiar list of recent and readily apparent risk themes. It pointed to interest rate and refinancing pressure, softening rent growth in over supplied metros, regulatory constraints, economic sensitivity and rising operating costs. Each of these risks is directionally reasonable and reflects current market narratives. However, they are presented as a loose collection of near-term pressures rather than as part of a coherent risk framework.
The ChatGPT response does not distinguish between cyclical headwinds and underlying structural risk, nor does it account for foundational factors such as industry maturity, competitive dynamics or long run demand drivers. There is also no consideration of forecast risk or how today’s pressures are expected to evolve over time. Without benchmarks, severity rankings or forward-looking context, the assessment sounds informed but remains subjective and incomplete. For example, the last bullet of ChatGPT’s risk assessment introduces the relationship between employment trends and industry health, but it doesn’t contextualize that information, leaving more research yet to be done.
Microsoft Copilot approaches the same question through 91ÉçÇř’s standardized risk scoring framework. Rather than listing risks in isolation, it assigns the US apartment rental industry an overall risk score of 4.81 out of 9, placing it in the medium risk category. That score is not based on a hazy memory of general trends. It is derived from a consistent methodology that evaluates growth risk, structural risk and sensitivity to external economic drivers.

This standardization is critical for professional analysis. By anchoring risk to a defined scoring system, Copilot minimizes the risk of hallucinated severity or inconsistent categorizations that LLMs can produce when reasoning from general knowledge. The framework also provides context. Industry risk is forecast to remain medium in 2026, lower than the US economy average and broadly in line with the broader real estate and rental and leasing sector. The Microsoft Copilot integration can also go further in analyzing structural risk, showing how sensitivity is tied explicitly to measurable drivers such as vacancy rates, unemployment, Treasury yields and urban population trends.
Instead of asking users to interpret a list of plausible risks, Copilot gives them a calibrated view of where the industry sits on the risk spectrum, supported by standardized scoring and forward-looking benchmarks. That consistency is what turns risk discussion into something that can be compared across portfolios, industries and time, rather than debated case by case.
Commercial banking: “Draft an executive summary of the US dentistry industry.”
When prompted to draft an executive summary of the US dentistry industry for a commercial loan write-up, ChatGPT produced a polished and lender-friendly narrative built around familiar healthcare themes. It described dentistry as a large, resilient sector characterized by fragmented ownership, recurring patient demand, and limited technological disruption. While directionally accurate, the analysis remained imprecise. In this case, the industry was broadly described as a $160 billion market without clarifying scope, growth trajectory or recent performance, and without distinguishing between necessity driven preventive care and more discretionary elective procedures. Key claims about demand stability and cash flow resilience were presented without verified benchmarks, current growth rates or forward-looking expectations.
Microsoft Copilot’s response, by contrast, immediately anchored the analysis in 91ÉçÇř’s structured industry data. It identified the industry by NAICS classification, cited current revenue of $179.4 billion, quantified historical growth at a 2.7 percent CAGR, and referenced a 1.8 percent growth forecast for 2025. These inputs transform the summary from a descriptive overview into an evidence-based credit narrative. Crucially, our Microsoft Copilot agent also enables relational querying across industries. From the same prompt, users can move seamlessly from the core Dentists industry to adjacent and niche reports such as Cosmetic Dentists in the US, allowing lenders to isolate discretionary exposure, assess subsegment risk and stress test repayment assumptions.
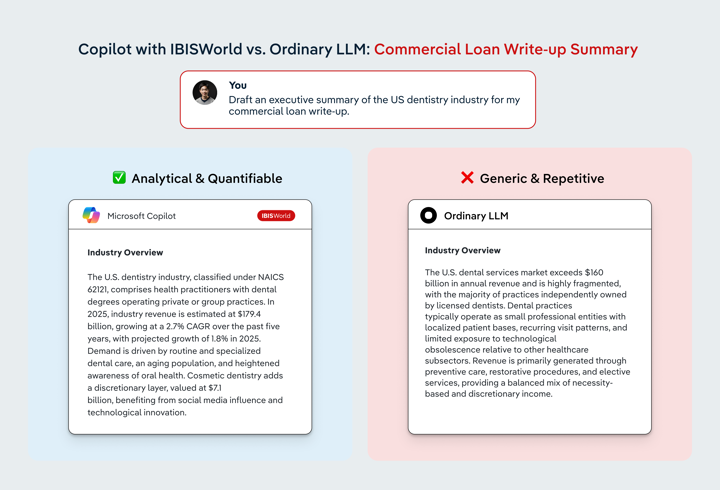
This is where the difference between free AI chatbots and 91ÉçÇř’s Copilot becomes most apparent. ChatGPT speaks confidently about the industry in general terms, but it cannot master the nuance beneath the surface. Our Microsoft Copilot agent reasons directly from organized, analyst-curated datasets, linking forecasts, subindustries and risk drivers in a way that supports real lending decisions rather than generic reassurance.
The limits of deep research and web search
Recent tools like promise to solve one of AI’s biggest weaknesses: outdated knowledge. The Deep Research model performs multi-step internet research needed to complete complex tasks. By allowing models to browse the web in real time, OpenAI ensures that its users are accessing fresh information and following leads across multiple sources. It’s a promising step toward “active” intelligence, where an LLM can quickly retrieve knowledge that it doesn’t already possess. But web access alone doesn’t guarantee good insight. These models can only be as strong as the material they have access to, and the internet remains an uneven landscape. Much of what’s freely available is shallow, repetitive or unreliable, while the most authoritative data—the kind that underpins serious decisions— increasingly sits behind paywalls or in proprietary databases (like 91ÉçÇř’s!). In practice, the open web gives models reach, but not necessarily depth or accuracy.
Even when sources are solid, Deep Research is slow by design. The iterative back-and-forth that makes it valuable for fetching, reading and reasoning over multiple pages also makes it cumbersome. As we saw in our examples, it’s a great way to explore a new topic, but not an efficient way to get trusted insight as you are advising your client or preparing for a board meeting.
Ultimately, real-time search can provide new information, but not necessarily reliable information. For that, AI still depends on structured, expert-curated context and credible datasets like 91ÉçÇř’s, where every figure and relationship has been verified and organized for reasoning.
Final Word
AI doesn’t invent intelligence; it inherits it from the data it’s trained on and the context it’s given.
Karpathy’s idea of “hazy recollection vs working memory” captures the next frontier in AI. Progress won’t come from ever-bigger models; it will come from better context, from feeding models structured, credible and timely information they can truly reason with.
That’s where trusted, human-verified research like 91ÉçÇř’s matters. For decades, our analysts have defined industries, mapped drivers and quantified the economy’s moving parts. Their structured reasoning gives AI the scaffolding it needs to move beyond pattern recognition to genuine understanding.
When AI stands on verified ground, executives, investors and policymakers can rely on its insight—not as a substitute for human judgment but as a powerful extension of it.








